Abstract
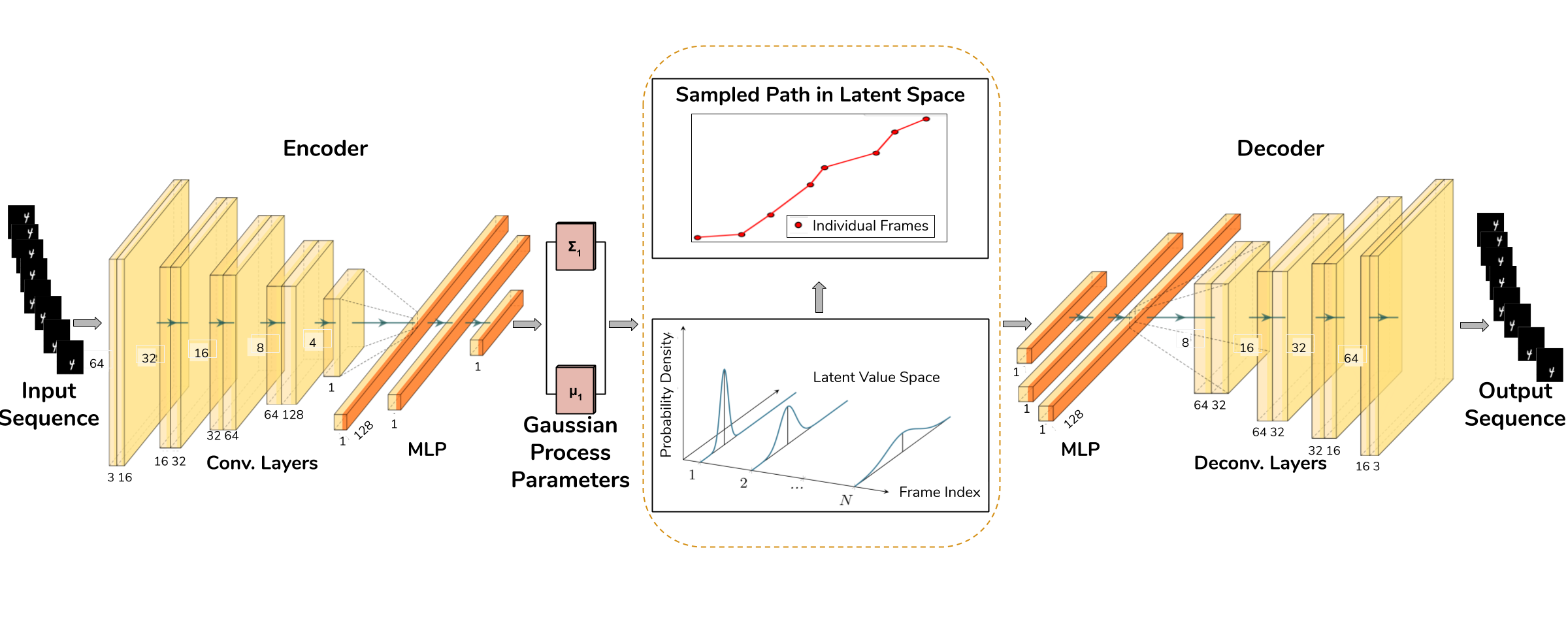
We introduce MGP-VAE (Multi-disentangled-features Gaussian Processes Variational AutoEncoder), a variational autoencoder which uses Gaussian processes (GP) to model the latent space for the unsupervised learning of disentangled representations in video sequences. We improve upon previous work by establishing a framework by which multiple features, static or dynamic, can be disentangled. Specifically we use fractional Brownian motions (fBM) and Brownian bridges (BB) to enforce an inter-frame correlation structure in each independent channel, and show that varying this structure enables one to capture different factors of variation in the data. We demonstrate the quality of our representations with experiments on three publicly available datasets, and also quantify the improvement using a video prediction task. Moreover, we introduce a novel geodesic loss function which takes into account the curvature of the data manifold to improve learning. Our experiments show that the combination of the improved representations with the novel loss function enable MGP-VAE to outperform the baselines in video prediction.
Please cite using following bibtex:
@article{Bhagat2020DisentanglingRU,
title={Disentangling Representations using Gaussian Processes in Variational Autoencoders for Video Prediction},
author={Sarthak Bhagat and Shagun Uppal and Vivian T. Yin and Nengli Lim},
journal={ArXiv},
year={2020},
volume={abs/2001.02408}
}
Style Transfer Results
Results from swapping latent channels in Moving MNIST; channel 1 (fBM(H = 0.1)) captures digit identity; channel 2 (fBM(H = 0.9)) captures motion.
Results from swapping latent channels in Coloured dSprites; channel 2 captures shape, channel 3 captures scale, channel 4 captures orientation and position, and channel 5 captures color.
Results from swapping latent channels in Sprites; channel 1 captures hair type, channel 2 captures armor type, channel 3 captures weapon type, and channel 4 captures body orientation.
Geodesic Loss for Video Frame Prediction
For video prediction, we predict the last k frames of a sequence given the first n − k frames as input. To do so, we employ a simple three-layer MLP (16 units per layer) with ReLU activation which operates in latent space rather than on the actual frame data so as to best utilize the disentangled representations. The first n − k frames are first encoded by a pre-trained MGP-VAE into a sequence of points in latent space. These points are then used as input to the threelayer MLP to predict the next point, which is then passed through MGP-VAE’s decoder to generate the frame. This process is then repeated k − 1 more times.
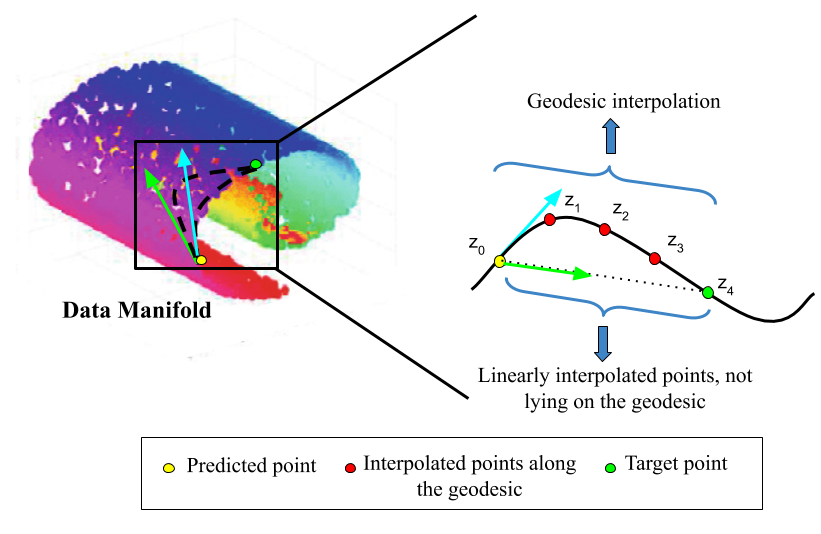
Using the geodesic loss function as compared to squared-distance loss for prediction. By setting the target as z1 instead of z4, the model learns more efficiently to predict the next point.

Predictions without using the geodesic loss function for Moving MNIST. The red boxes illustrate the target frame (top row) and predicted frame (bottom row).

Predictions with using the geodesic loss function for Moving MNIST. The red boxes illustrate the target frame (top row) and predicted frame (bottom row).
Video Frame Prediction Results

Qualitative results of MGP-VAE and the baselines in the video prediction task for Moving MNIST Dataset. Predicted frames are marked in red, and the first row depicts the original video sequence.
Qualitative results of MGP-VAE and the baselines in the video prediction task for Colored dSprites Dataset. Predicted frames are marked in red, and the first row depicts the original video sequence.
Qualitative results of MGP-VAE and the baselines in the video prediction task for Sprites Dataset. Predicted frames are marked in red, and the first row depicts the original video sequence.